Mit dem Open Policy Agent Deine Datenzugänge sicher im Griff haben
Autor: Christian Sanabria
Data Centric Security, Rule Based Access Control, Policy Based Authorization. Viele Begriffe, die alle dasselbe meinen: Eine Zugriffskontrolle, welche über klassische Rollenkonzepte und Role Based Access Control hinausgeht. Doch wie und warum soll man eine solche umsetzen?
In diesem Blog will ich mich anhand von zwei Use-Cases aus dem Banken- und Versicherungs-Kontext auf die fachlichen Anforderungen fokussieren und zeigen, wie sie sich mit dem Open Policy Agent (OPA) technisch umsetzen lassen. Dabei handelt es sich um folgende Use-Cases:
- Stellvertreterregelung eines Kundenberaters bei einer Privatbank
- Vertrauliche Dokumente im Kontext einer Familienpolice bei einer Krankenkasse
Diese Use-Cases sind typische Beispiele, die sich als Vorlagen für weitere und auch komplexere Anwendungsfälle verwenden lassen. Bei beiden Use-Cases geht es darum, dass Zugriffe auf sensitive und kritische Informationen sehr selektiv und individuell kontrolliert werden müssen. Es muss somit sichergestellt sein, dass zum richtigen Zeitpunkt ausschliesslich die richtige Person Zugang hat.
Zusätzlich wird in diesem Blog noch auf die technischen Vorteile des OPAs eingegangen sowie die Testbarkeit von Regeln und Live-Update-Möglichkeiten von Policies aufgezeigt. Zuletzt werden die flexiblen Integrationsmöglichkeiten des OPA’s als zentrale Entscheidungsstelle für Anfragen auf Datenzugriffe thematisiert.
Warum überhaupt auf datenzentriere Sicherheit setzen
Gemäss Best Practices nach Zero Trust [1] müssen Autorisierungsentscheidungen datenzentriert anstatt rollenbasiert umgesetzt werden. Das liegt daran, dass die datenzentrierte Sicherheit Technologien und Prozesse umfasst, welche den Schwerpunkt auf der Erfassung, Speicherung, Speicherort und Sichtbarkeit von Daten legen. Dieser Sicherheitsansatz zielt darauf ab, Daten während ihres gesamten Lebenszyklus zu schützen.
Herkömmliche Ansätze (wie rollenbasierte Sicherheit) beinhalten hingegen nur die Sicherung von Netzwerken, Servern und Anwendungen. Das reicht nicht, denn so hat potenziell eine viel zu grosse Population an Benutzern Zugriff auf kritische Daten.
Deshalb geht meine Empfehlung in Richtung datenzentrierte Sicherheit, da deren Datenschutz unabhängig davon ist, wer einen Zugriffsversuch unternimmt oder mit wem die Daten geteilt wurden.
Möchtest Du die datenzentrierte Sicherheit in deinem Unternehmen verankern, dann musst Du dich mit nachfolgenden fünf Schlüsselementen und Fragestellungen auseinandersetzen:
- Identifizieren: Welche Daten habe ich?
- Verstehen: Aus welchen Quellen stammen die Daten?
- Kontrollieren: Sind Kontrollmechanismen bereitgestellt?
- Schützen: Ist das korrekte Level an Datenschutz implementiert?
- Auditieren: Sind Zugriffe protokolliert? Von wem, von wo, wie, wann und warum?
Die Elemente 1 und 2 sind unverzichtbare Vorarbeiten, um überhaupt mit datenzentrierter Sicherheit zu beginnen. Du musst wissen, welche Daten Du hast und von wo diese Daten stammen, d.h. ob sie z.B. regulatorischen Auflagen unterliegen.
Die Elemente 3 bis 5 bilden dabei die Grundlage für die technische Einführung der datenzentrierten Sicherheit, da diese direkt als funktionale und nicht-funktionale Anforderungen in die Implementierung einfliessen.
Wie führe ich datenzentrierte Sicherheit ein
Für die Umsetzung von datenzentrierter Sicherheit bietet sich ‘Policy Based Authorization’ an. Dies ist eine regelbasierte Autorisierung. Für Systeme, welche regelbasierte Autorisierungen anbieten, hat sich in den letzten Jahren eine Standardarchitektur etabliert:
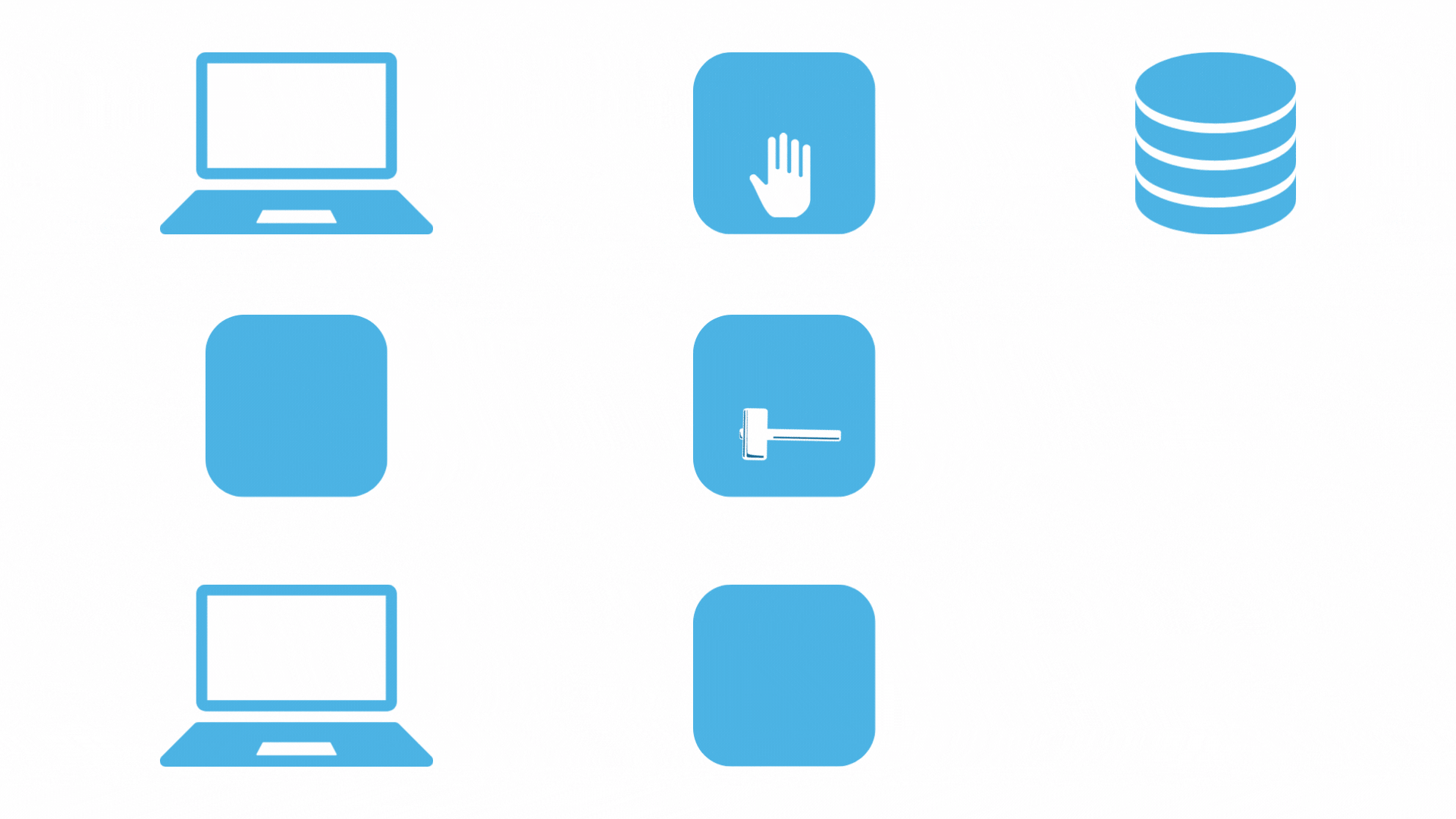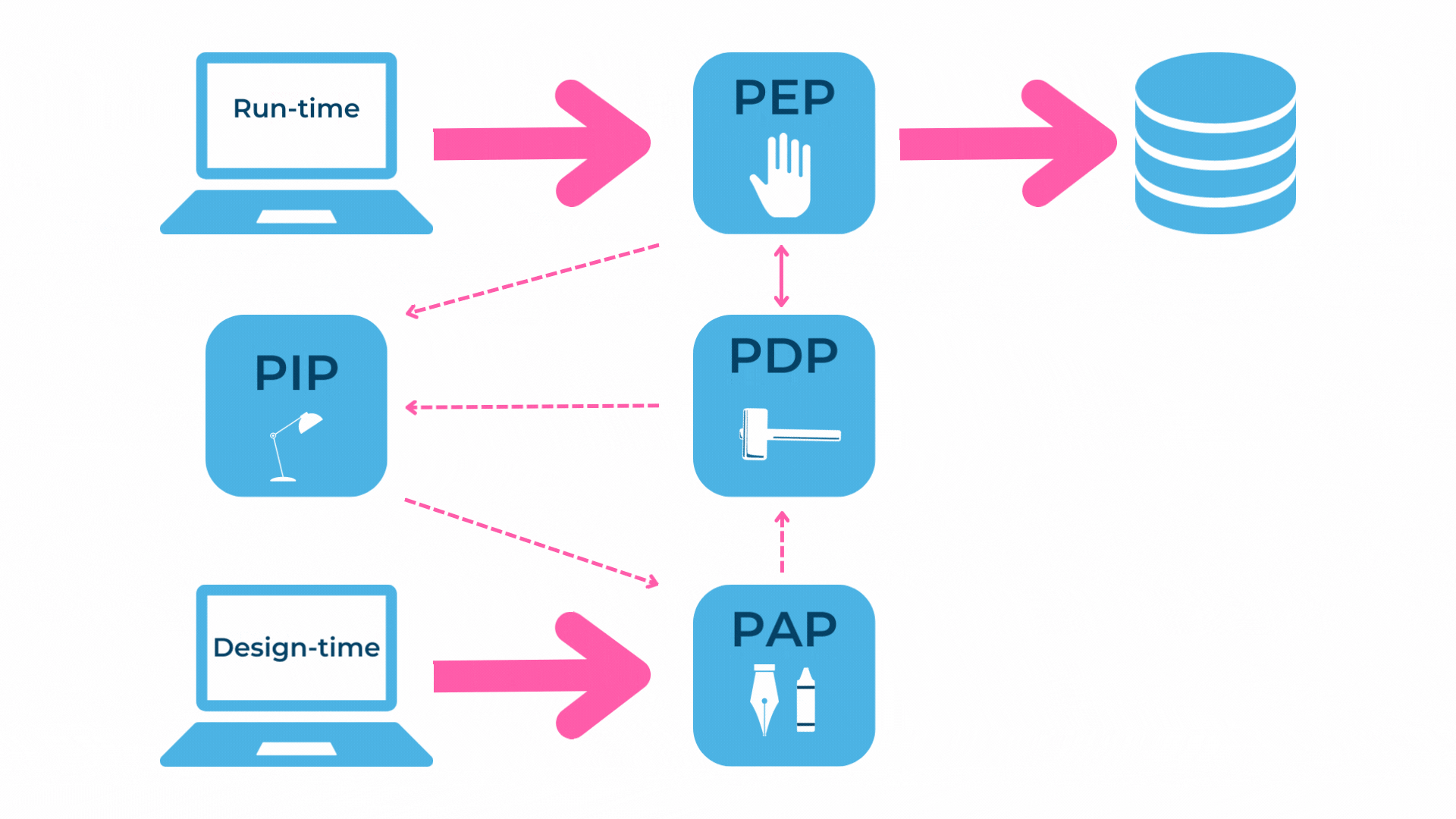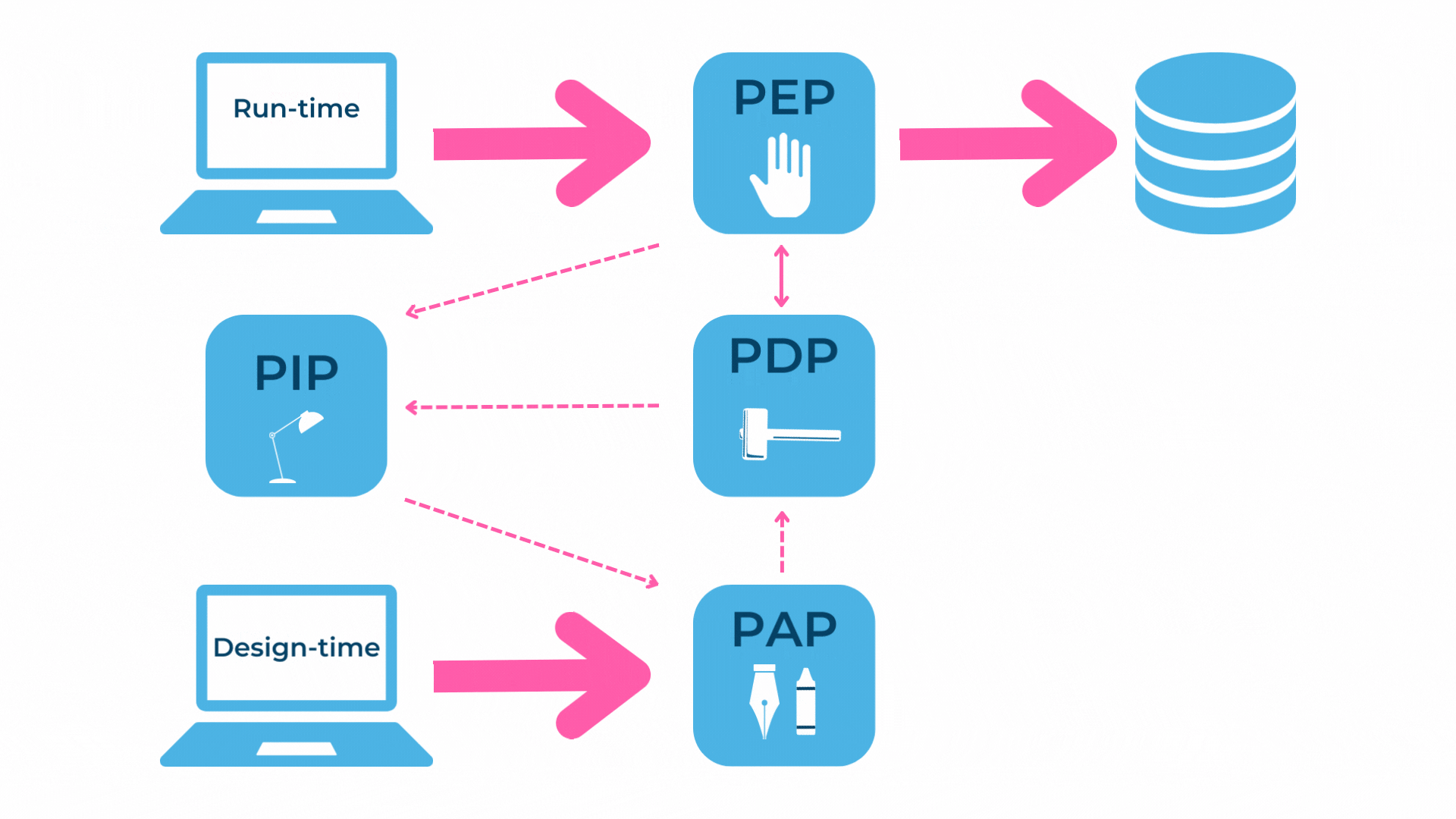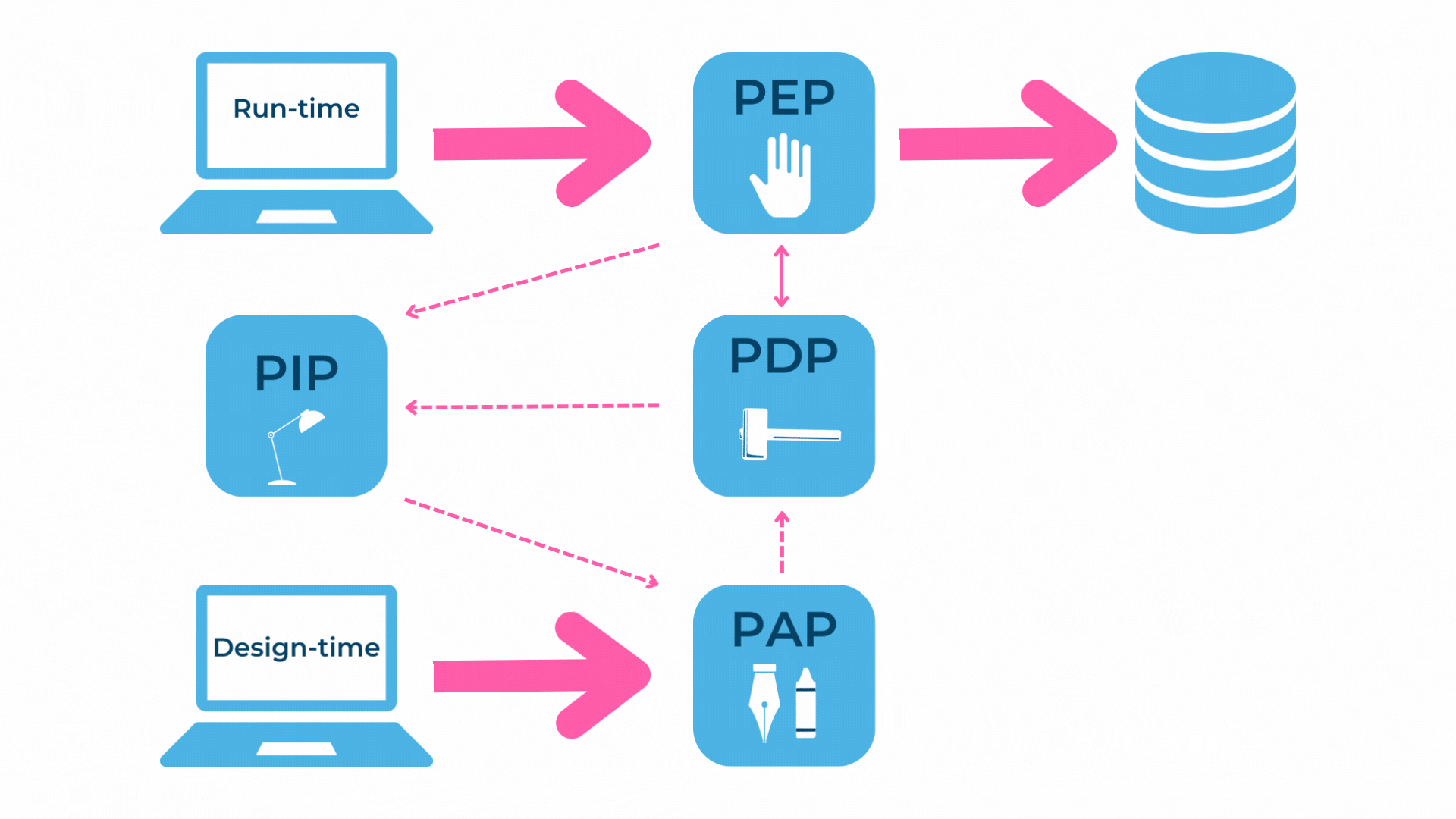
Im Blog von Ryan Aebi ist diese Standardarchitektur für ein datenzentriertes Autorisierungssystem auf Basis von Policies ebenfalls abgebildet und auch ausführlicher erklärt.
Zusammengefasst sind folgende Komponenten beteiligt und für die Umsetzung unserer zwei Use Cases von Relevanz:
- Policy Enforcement Point (PEP): Setzt einen Entscheid für einen Request um
- Policy Decision Point (PDP): Fällt die Entscheidung, ob ein Zugriff erlaubt ist
- Policy Information Point (PIP): Definiert die Policies für die Entscheidungsgrundlage
- Policy Administration Point (PAP): Verwaltet die verfügbaren Policies
Die bekannteste Implementation einer solchen Architektur ist XACML [3], welches seit 2001 als Standard vorliegt und 2013 mit Version 3.0 die letzte grosse Überarbeitung erhielt.
Der Standard basiert auf XML und ist durch seine Maturität ausserordentlich mächtig, dadurch aber auch komplex in der Anwendung. Existierende Produkte benötigen Expertenwissen und lassen sich nur schwer in eine moderne IT-Landschaft integrieren.
Als Lösung für dieses Problem bietet sich der Open Policy Agent (OPA) [4] an. Der OPA ist eine quelloffene Policy Engine, also eine Sammlung von Komponenten, die eine einheitliche und effiziente Umsetzung von Regeln aller Art erlaubt.
Verfügbar ist der OPA als Open Source mit Basisfunktionalität oder in einer kommerziellen Variante [5] mit zusätzlichen Features. Die nachfolgende Abbildung zeigt ein mögliches Funktionsbeispiel vom OPA auf. Zudem findest Du im Blog von Ryan Aebi eine vertiefte Diskussion zum OPA.
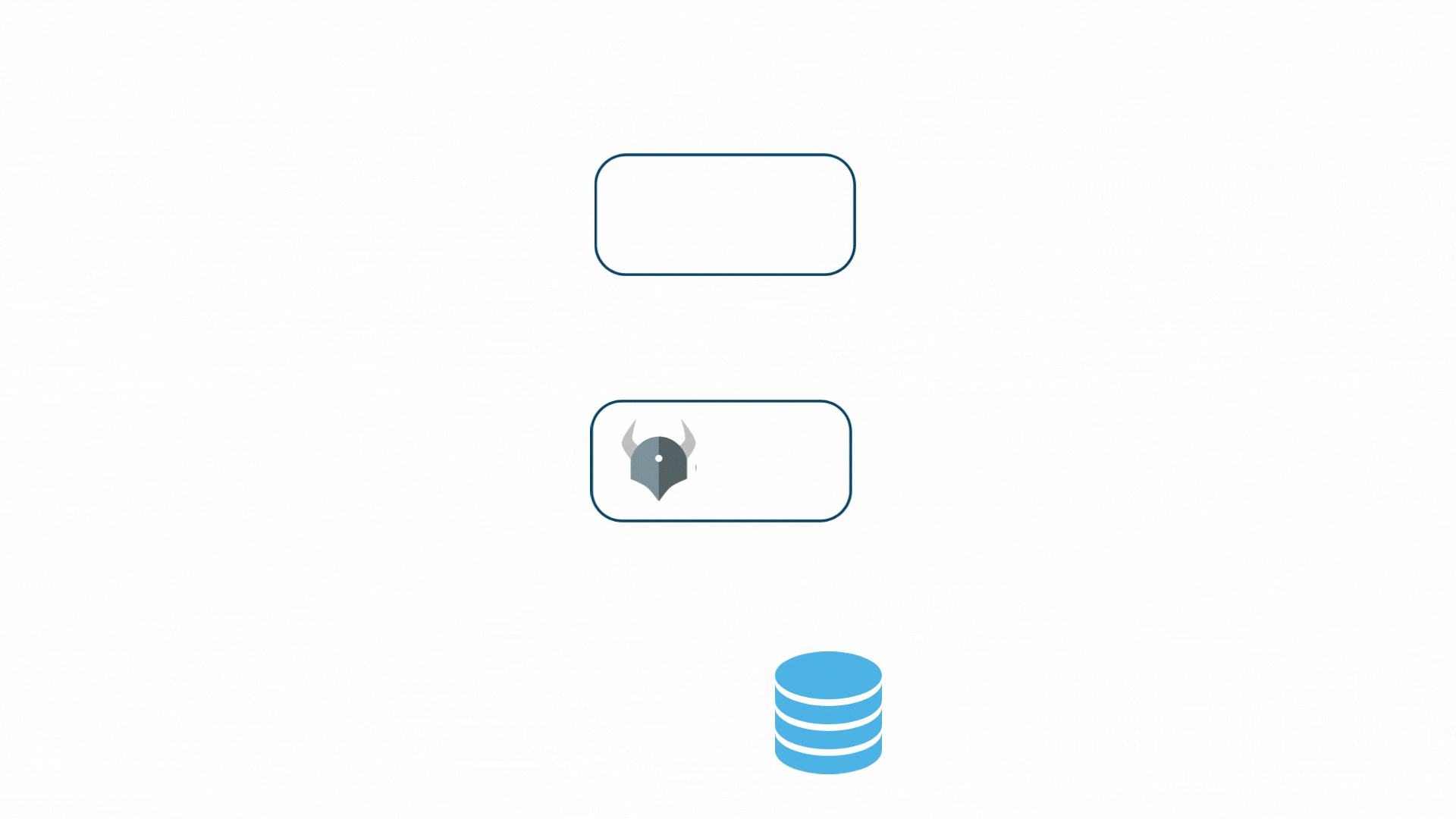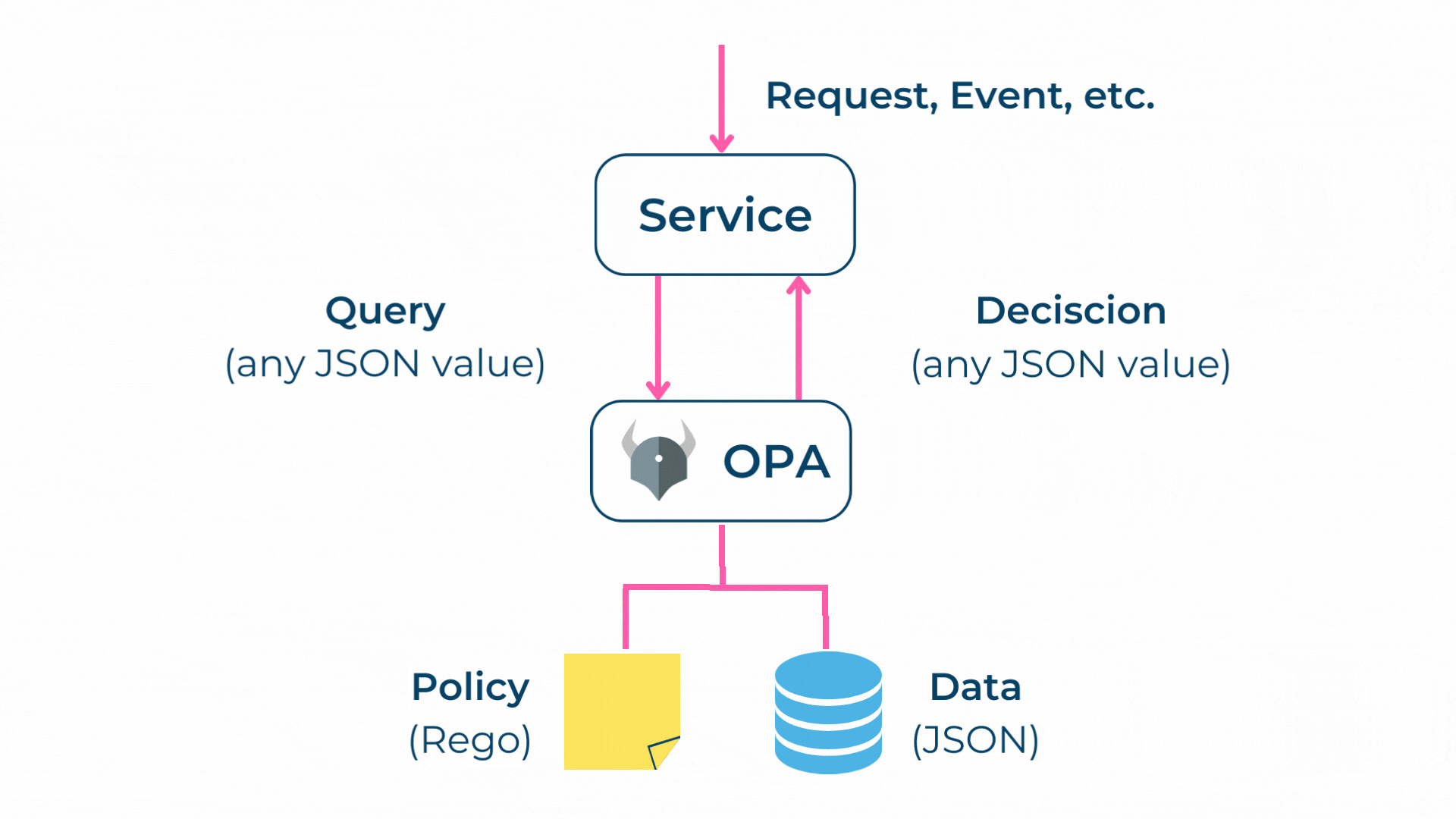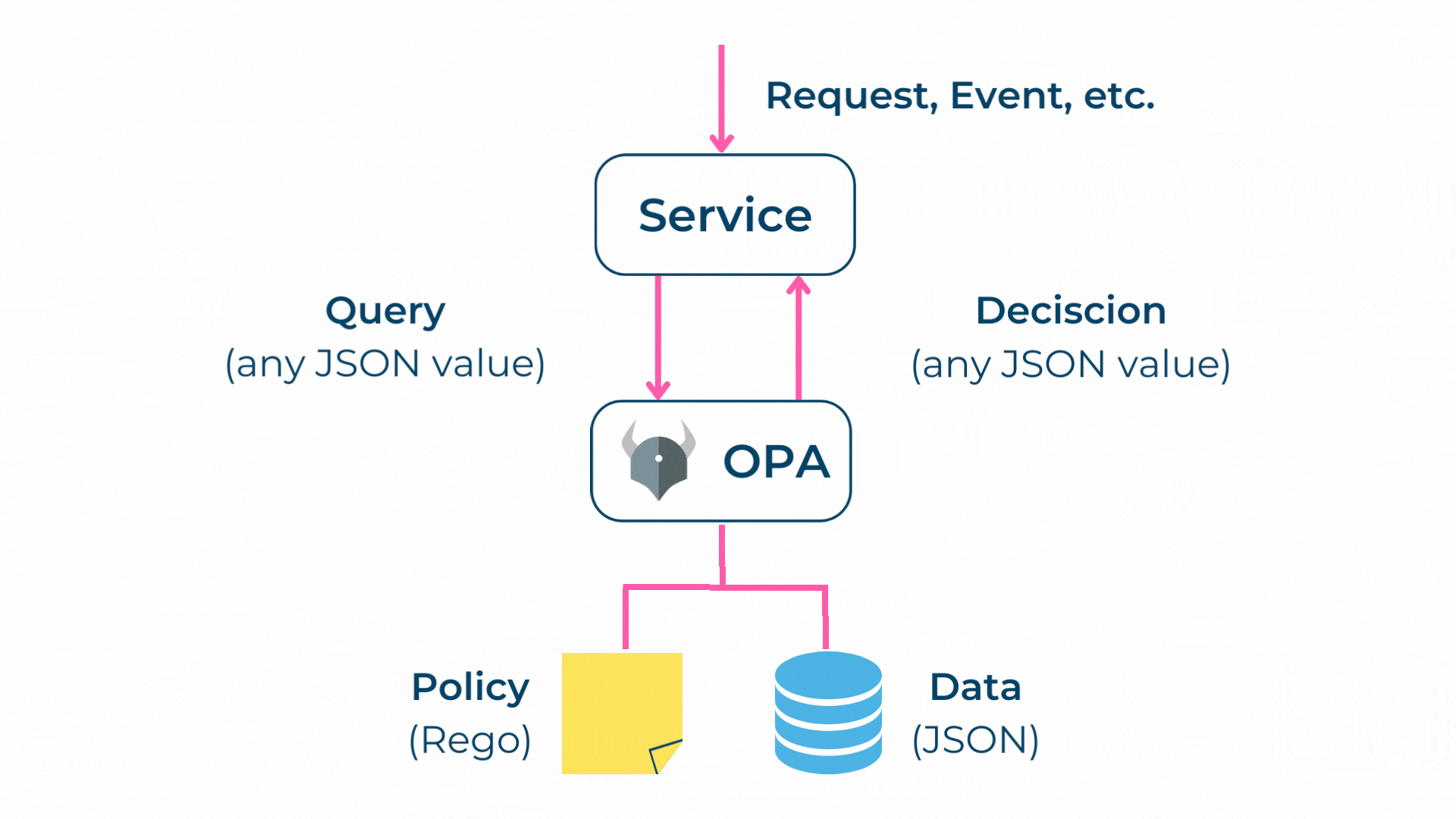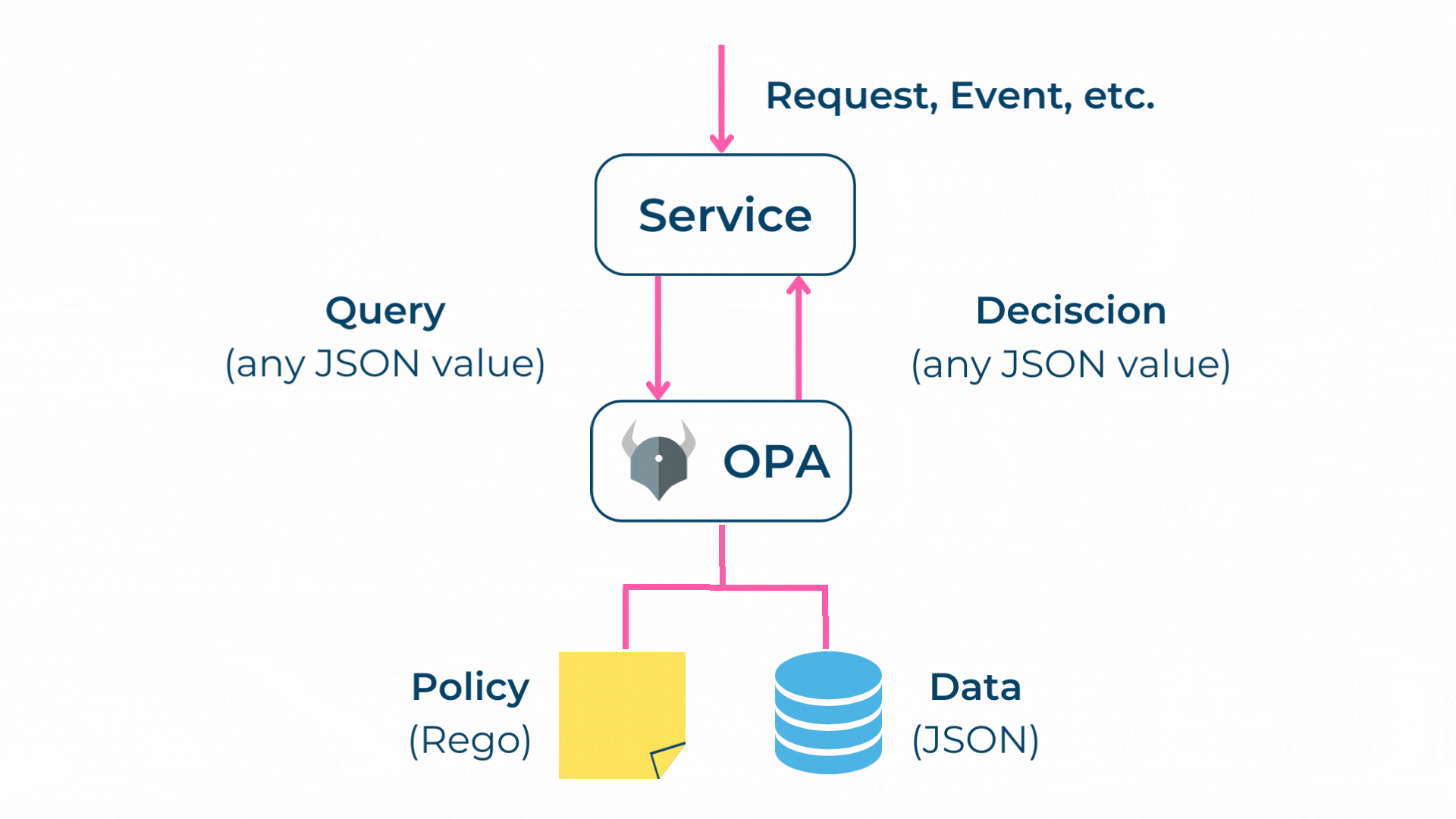
Der OPA erlaubt es, Policies als Code zu verwalten und auszuführen. Zusätzlich stellt der OPA Query-Schnittstellen, also Schnittstellen für die Datenabfrage, für unterschiedliche Anwendungsfälle zur Verfügung.
Policies selbst werden in Rego [6] geschrieben, was eine deklarative Sprache ist, bei welcher auf das gewünschte Ergebnis fokussiert wird. Somit können sich Policy-Autoren darauf konzentrieren, was Queries zurückgeben sollen, anstatt wie Queries ausgeführt werden.
In diesem Sinne fungiert der Open Policy Agent als Policy Decision Point (PDP) und als Policy Information Point (PIP). Als Policy Administration Point (PAP) kann jede beliebige IDE verwendet werden. Als Policy Enforcement Point (PEP) können diverse Systeme wie Proxies oder Gateways eingesetzt werden.
Doch wie sieht das alles in der Praxis aus?
Open Policy Agents in Action: Zwei Use Cases
Nachfolgend werden zwei typische Use-Cases aus dem Banken- und Versicherungs-Kontext beschrieben. Mit der datenzentrierter Security lassen sich diese Use-Cases effizienter und einfacher umsetzen als mit klassischen Rollenkonzepten.
Für beide Use-Cases gelten dabei ähnliche Ausgangslagen:
- In beiden Fällen hat der Benutzer über eine Rolle Zugriff auf die entsprechenden Datentöpfe (Kundendaten bzw. Dokumente).
- In beiden Fällen liefert das aufrufende System einen externen Kontext als Query an den OPA.
- In beiden Fällen wird aus externen Systemen ein Dataset mit den relevanten internen Kontextinformationen (z.B. aus einem IAM- oder einem CRM- System) für den OPA bereitgestellt.
Use-Case 1: Stellvertreterregelung eines Kundenberaters bei einer Privatbank
Kundenberater haben ihr eigenes Set an zu verwaltenden Kunden, auf deren verteilte Daten (Konti, Beziehungen, Archive) nur sie und allenfalls auch Teamleiter Zugriff haben. Aus diversen Gründen (wie Ferien, Krankheit) sind zeitlich begrenzte Stellvertreterregelungen nötig und unterschiedlichste Personen benötigten temporären Datenzugriff.
Wie nun Kontext und Regeln für diesen Use-Case aussehen könnten, ist in der nachfolgenden Umsetzung als Beispiel beschrieben.
Query - Externer Kontext
Die Query für diesen Use-Case enthält die Benutzerkennung des Kundenberaters, für welchen die Entscheidung getroffen werden muss, sowie die angefragte Kundennummer:
{
“user”: “user-id-1”,
“customer”: “customer-id-2”
}
Data - Interner Kontext
Für Use-Case 1 wird im Data-Teil als interner Kontext ein Mapping der Benutzerkennung zu erlaubten Kundennummern inkl. Gültigkeit gespeichert:
- user-id-x: Registrierte Kundenberater
- customer-id-x: Gespeicherte Kundennummern
[
“user-id-1”:
[
“customer-id-1”:
{
“from”: “01.01.2023”,
“until”: “31.12.2023”
},
“customer-id-2”: {
“from”: “20.03.2023”,
“until”: “26.03.2023”
}
],
“user-id-2”:
[
“customer-id-2”:
{
“from”: “01.01.2023”,
“until”: “31.12.2023”
}
]
]
Policy / Decision - Entscheidung
Somit hat der OPA alle Kontextdaten, um eine Entscheidung über den Zugriff auf den definierten Kunden zu treffen. Die Policy dazu sieht in Rego-Code wie folgt aus:
main {
is_customer_allowed
is_date_in_range
}
is_customer_allowed {
acc := data[input.user][input.customer]
acc != null
}
is_date_in_range {
acc := data[request.user][input.customer]
from := time.parse_ns(“dd.MM.yyyy”, acc.from)
until := time.parse_ns(“dd.MM.yyyy”, acc.until)
now := time.now_ns()
from < now ; until > now
}
Die Policy evaluiert in diesem Fall wie folgt:
- is_customer_allowed: Hat der Benutzer (user-id-1) eine Berechtigung auf den abgefragten Kunden / dessen Daten (customer-id-2)? → TRUE
- is_date_in_range: Befindet sich das aktuelle Systemdatum (Bsp: 05.04.2023) im Range für den erlaubten Zugriff? → FALSE (Das Datum 05.04.2023 ist ausserhalb des Bereiches 20.03.2023 bis 26.03.2023, und somit hat user-id-1 keinen Zugriff mehr auf die customer-id-2).
Use-Case 2: Vertrauliche Dokumente einer Familienpolice bei einer Krankenkasse
Der Vorstand einer Familienpolice hat Zugriff auf alle Dokumente innerhalb des Vertrages (Rechnungen, Behandlungen, Gesundheitsberichte). Partner und auch Kinder ab einem Alter von spätestens 16 Jahren haben aber auch das Recht darauf, dass gewisse Daten nur durch sie selbst, aber nicht durch den Familienvorstand eingesehen werden dürfen.
Die Umsetzung für diesen Use-Case mit dem entsprechenden Kontext und benötigten Regeln sind nachfolgend als Beispiel beschrieben.
Query - Externer Kontext
Für diesen Use-Case besteht die Query aus der Benutzerkennung des Familienmitglieds, welches das Dokument einsehen will, und der angefragten Dokumentennummer:
{
“user”: “user-id-1”,
“document”: “document-id-2”
}
Data - Interner Kontext
Für Use-Case 2 werden im Data-Teil ein Mapping von Dokumentennummern zu Benutzerkennungen sowie das Alter von einzelnen Benutzern gespeichert:
- user-id-x: Registrierte Dokumentinhaber
- document-id-x: Gespeicherte Dokumentnummern
{
“document-id-1”: [“user-id-1”],
“document-id-2”: [“user-id-1”, “user-id-2”],
“document-id-3”: [“user-id-3”]
}
{
“user-id-1”: 44,
“user-id-2”: 17,
“user-id-3”: 34
}
Policy / Decision - Entscheidung
Mit diesen Kontextdaten kann nun der OPA entscheiden, ob der Benutzer das Recht hat, dieses Dokument zu laden. Folgende Policy in Rego-Code wird dazu erstellt:
main {
is_document_allowed
has_alternate_owner
is_alternate_owner_allowed
}
is_document_allowed {
input.user in data[input.document]
}
has_alternate_owner {
alternate := data[input.document][1]
alternate != null
}
is_alternate_owner_allowed {
alternate := data[input.document][1]
data[alternate] < 16
}
In diesem Fall überprüft die Policy wie folgt:
- is_document_allowed: Ist der Benutzer (user-id-1) Inhaber des abgefragten Dokuments (document-id-2)? → TRUE
- has_alternate_owner: Gibt es für das abgefragte Dokument alternative / weitere Inhaber? → TRUE
- is_alternate_owner_allowed: Hat der alternative Inhaber (user-id-2) ein jüngeres Alter als 16? → FALSE (user-id-2 ist 17, und somit hat user-id-1 keinen Zugriff mehr auf die document-id-2).
Fazit
Die beiden Use-Cases demonstrieren sehr schön, wie sich komplexe Autorisierungsentscheidungen an den OPA delegieren lassen. Die Syntax der Policies ist einfach zu verstehen, aber gleichzeitig bieten sie auch weiterführende Konstrukte. Zum Beispiel Aufrufe von externen Systemen, um auch "near-real-time" Anpassungen an Kontextdaten oder Policies zu unterstützen. Dies ist bei der Umsetzung von Sanktionen (wie aktuell im Falle von Russland) oder bei der Behandlung von speziellen Personen (zum Beispiel Neu-VIPs) ein enormer Vorteil.
Einer der grössten Vorteile von OPA und Rego als Policy-Sprache ist aber die Fähigkeit, diese vor dem Ausrollen ausgiebig zu testen. Sowohl lokal zur Entwicklungszeit, aber auch in einer CICD-Pipeline, einer Methode zur Automatisierung im Rahmen der Softwarentwicklung, in Form von Regressionstests. So kann sichergestellt werden, dass Policies korrekt funktionieren und auch Edge-Cases nicht ohne weiteres durchschlüpfen.
Nice to know
Resümee
Kehren wir zu den fünf Schlüsselelementen der datenzentrierten Sicherheit zurück:
- Identifizieren
- Verstehen
- Kontrollieren
- Schützen
- Auditieren
Wie zu Beginn des Blogs beschrieben, sind die Punkte 1 und 2 vom OPA unabhängige Vorarbeiten. Diese Vorarbeiten sind jedoch zwingend, um die technisch relevanten Punkte 3 bis 5 adressieren zu können. Mit dem OPA werden die Punkte 3 bis 5 wie folgt angegangen und umgesetzt:
- 3. Kontrollieren: Die Rego Policysprache erlaubt es, für unterschiedlichste Systeme und Anwendungsfälle einheitliche Regeln zu erstellen und auch zentral bereitzustellen, welche überall bei Bedarf eingebunden werden können.
- 4. Schützen: Der OPA kann in unterschiedlichen PEPs (z.B. in API Gateways, Service Mesh, Kafka) integriert werden, wodurch Autorisierungsentscheidungen immer dort getroffen werden, wo sie für eine Zero Trust Infrastruktur erforderlich sind.
- 5. Auditieren: Über den OPA gemanagte Kontextdaten und Policies sowie die zentrale Engine lassen sich Entscheidungen immer transparent protokollieren und nachvollziehen, egal wer oder welches System die Anfrage stellt.
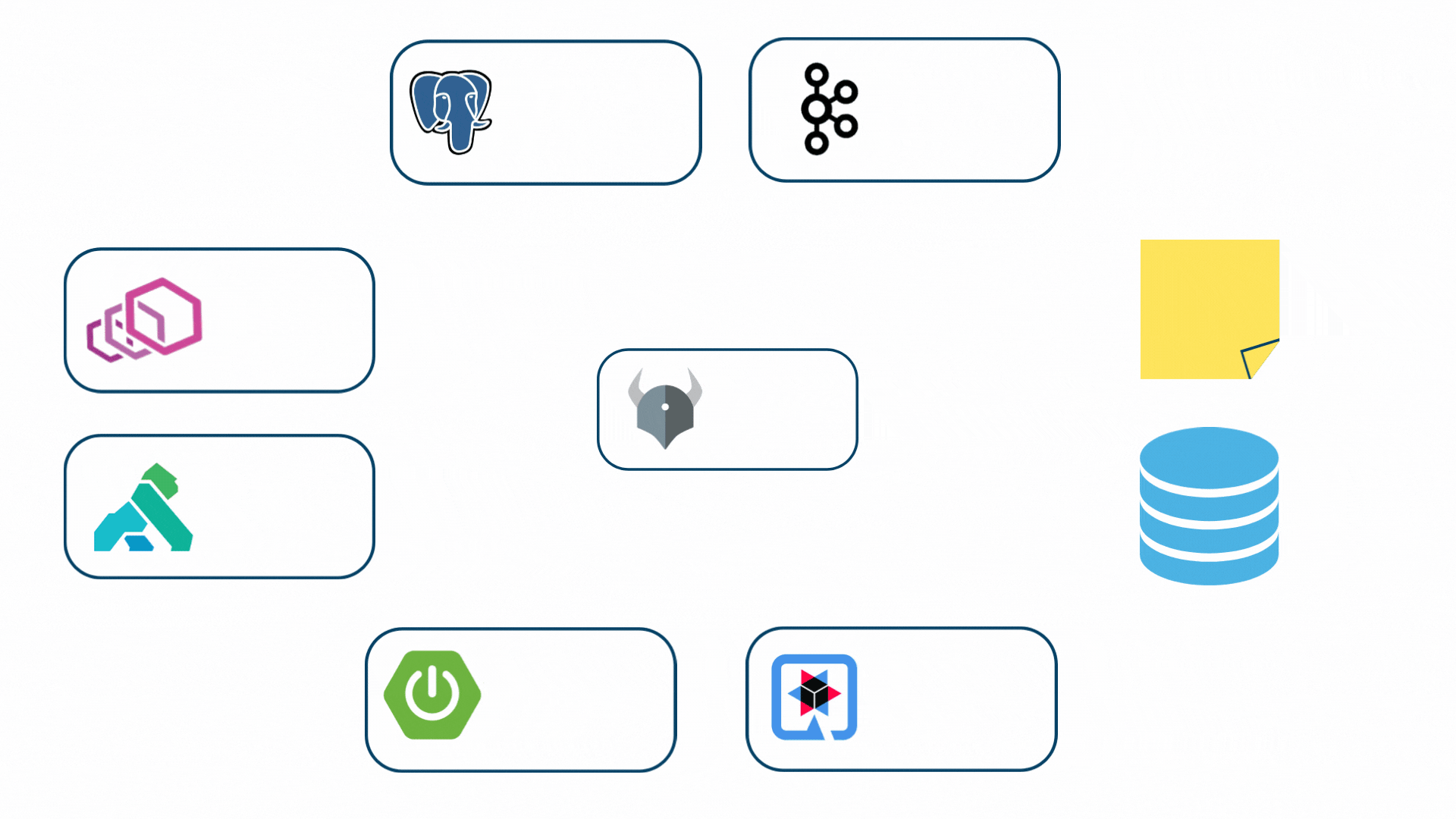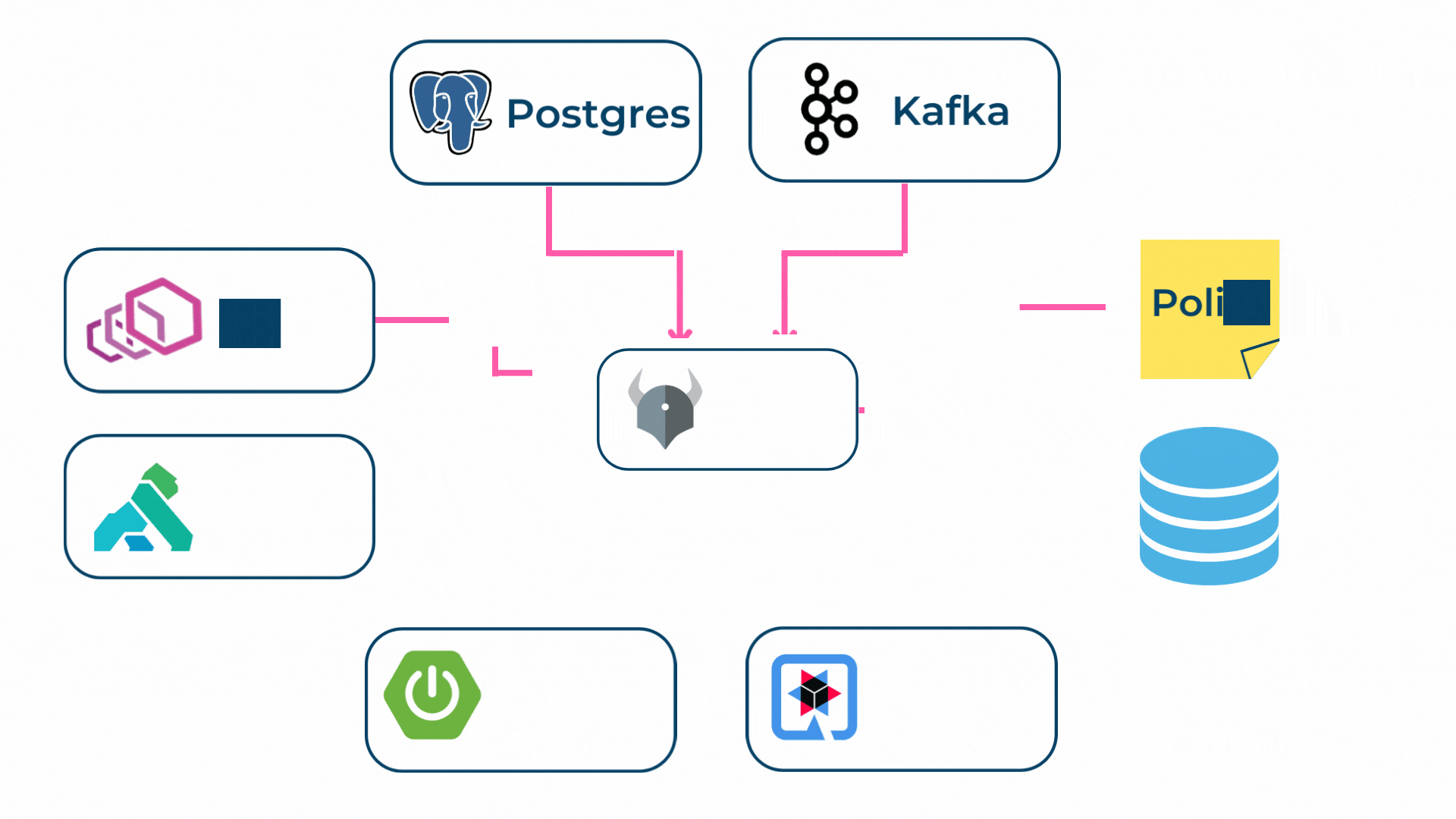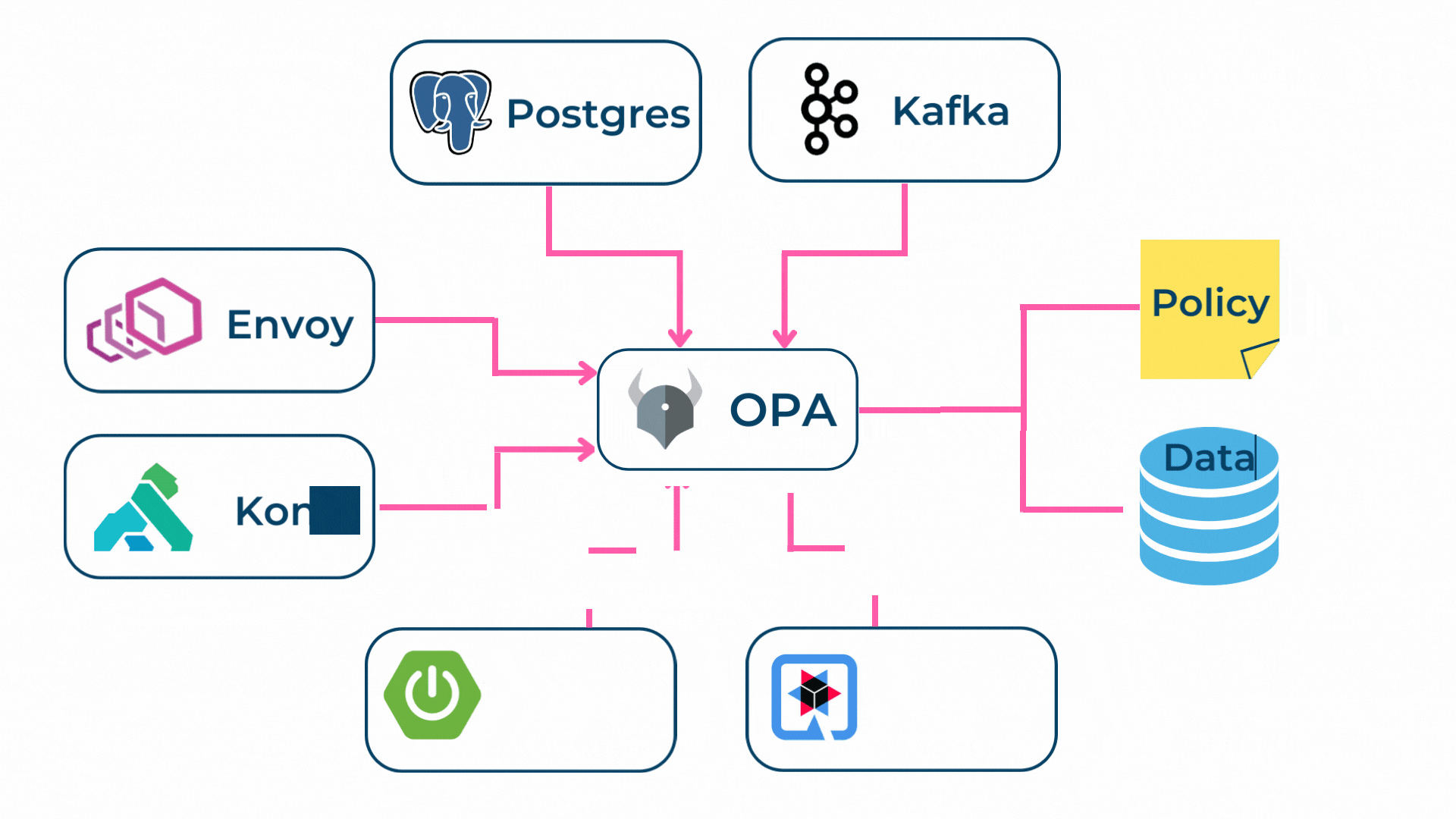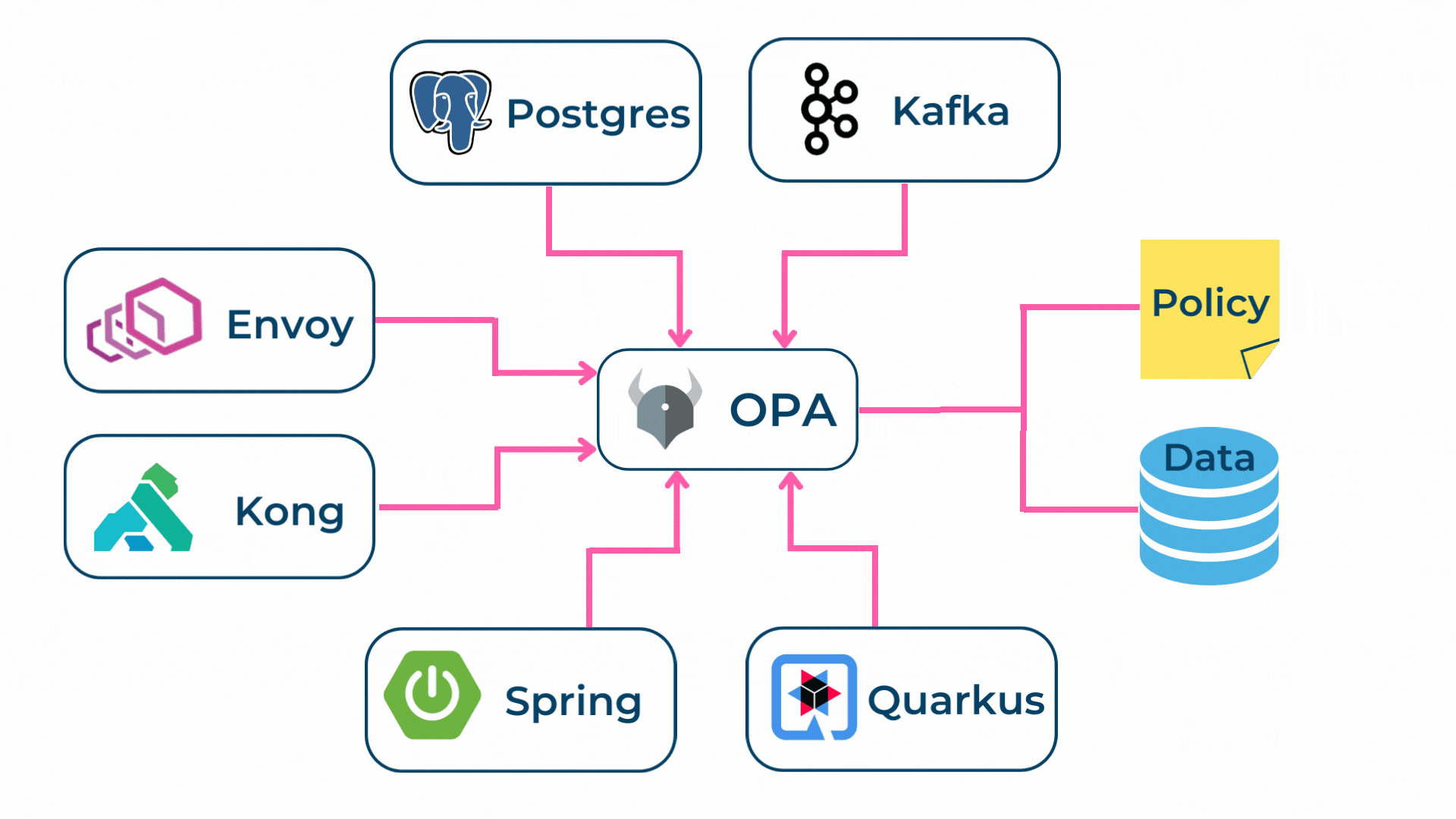
Somit kann in komplexen Systemen die Data Governance auf einfache Art durchgesetzt werden, ohne dass jede Komponente eigene Regeln oder Custom Code schreiben muss.
Dies erhöht zum einen die allgemeine Sicherheit und erlaubt auch schnelle Reaktionszeiten in Ausnahmefällen, weil Anpassungen an Policies oder Kontextdaten im besten Fall sofort auf allen PEPs verfügbar sind.
Referenzen
[1] Zero Trust Ressourcen
- Zero Trust Advancement Center (CSA)
- Jericho Forum Commandments
- What ist Zero Trust? (Azure)
- BeyondCorp – A new approach to enterprise security (Google)
[3] OASIS eXtensible Access Control Markup Language (XACML) TC
[4] Policy-based control for cloud native environments

Über mich
Saubere Architekturen liegen mir als IT-Architekt am Herzen. Diese ermöglichen es mir, Themen wie Security und Integration einfach in meine Lösungen einzubringen und in hoher Qualität umzusetzen.